Software Architecture¶
The fd.io vpp implementation is a third-generation vector packet processing implementation specifically related to US Patent 7,961,636, as well as earlier work. Note that the Apache-2 license specifically grants non-exclusive patent licenses; we mention this patent as a point of historical interest.
For performance, the vpp dataplane consists of a directed graph of forwarding nodes which process multiple packets per invocation. This schema enables a variety of micro-processor optimizations: pipelining and prefetching to cover dependent read latency, inherent I-cache phase behavior, vector instructions. Aside from hardware input and hardware output nodes, the entire forwarding graph is portable code.
Depending on the scenario at hand, we often spin up multiple worker threads which process ingress-hashes packets from multiple queues using identical forwarding graph replicas.
VPP Layers - Implementation Taxonomy¶
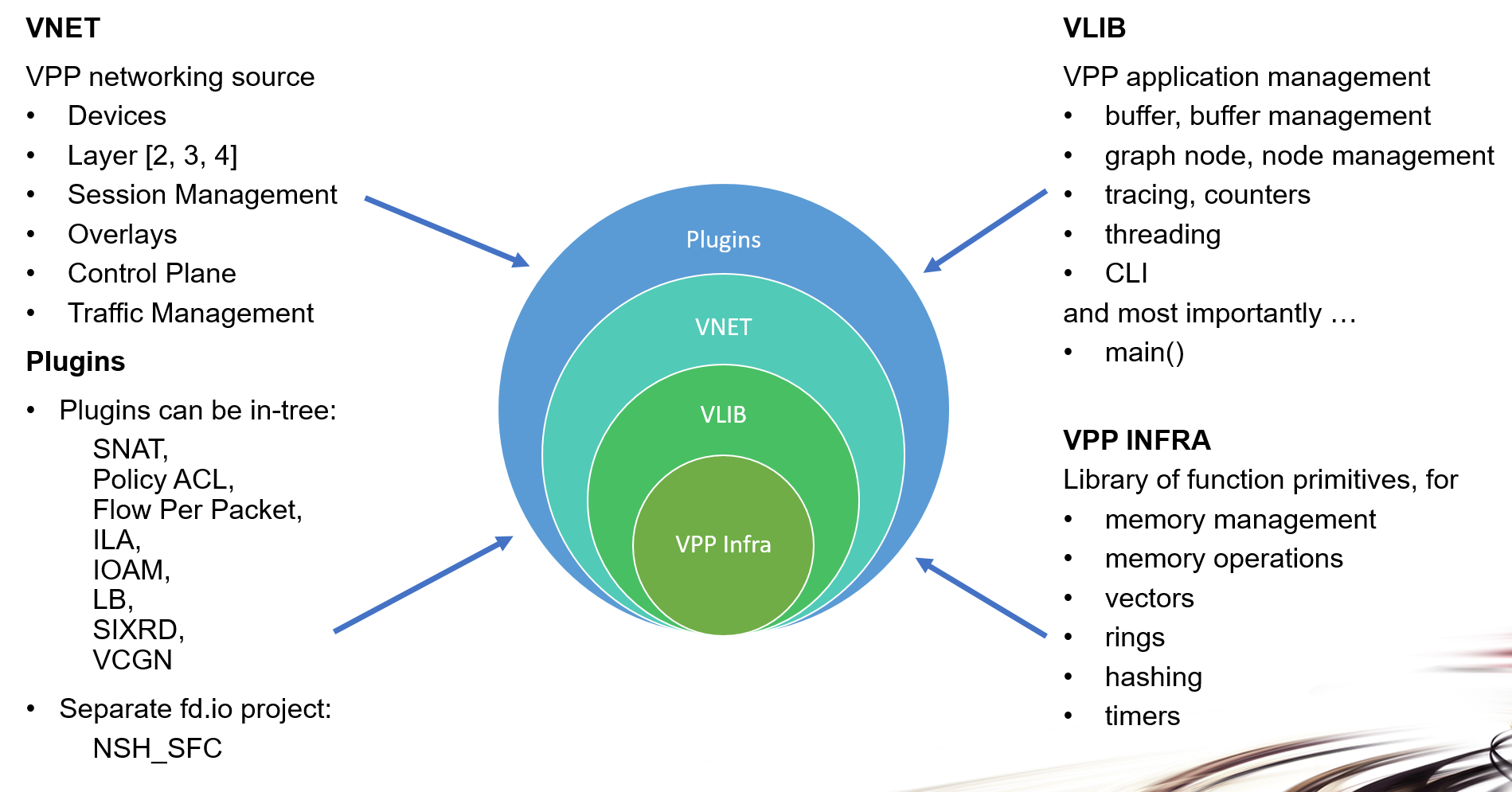
VPP Infra - the VPP infrastructure layer, which contains the core library source code. This layer performs memory functions, works with vectors and rings, performs key lookups in hash tables, and works with timers for dispatching graph nodes.
VLIB - the vector processing library. The vlib layer also handles various application management functions: buffer, memory and graph node management, maintaining and exporting counters, thread management, packet tracing. Vlib implements the debug CLI (command line interface).
VNET - works with VPP’s networking interface (layers 2, 3, and 4) performs session and traffic management, and works with devices and the data control plane.
Plugins - Contains an increasingly rich set of data-plane plugins, as noted in the above diagram.
VPP - the container application linked against all of the above.
It’s important to understand each of these layers in a certain amount of detail. Much of the implementation is best dealt with at the API level and otherwise left alone.